6 Triage
Not all websites and data files are of equal risk of being unrecoverable. Thanks to the Internet Archive and the work of groups like ArchiveTeam, many copies of at-risk sites and data have already been made. In time-sensitive situations, care should be taken to prioritize data that is less likely to be backed up and retrievable at a later date.
6.1 Low concern: statically-linked files
Of least concern are files that are statically-linked, i.e. files that are shown at the bottom left of your browser window when you hover your mouse over them. For example, see the following screenshot of a page that lists data downloads from the CDC Youth Risk Behavior Surveillance System:
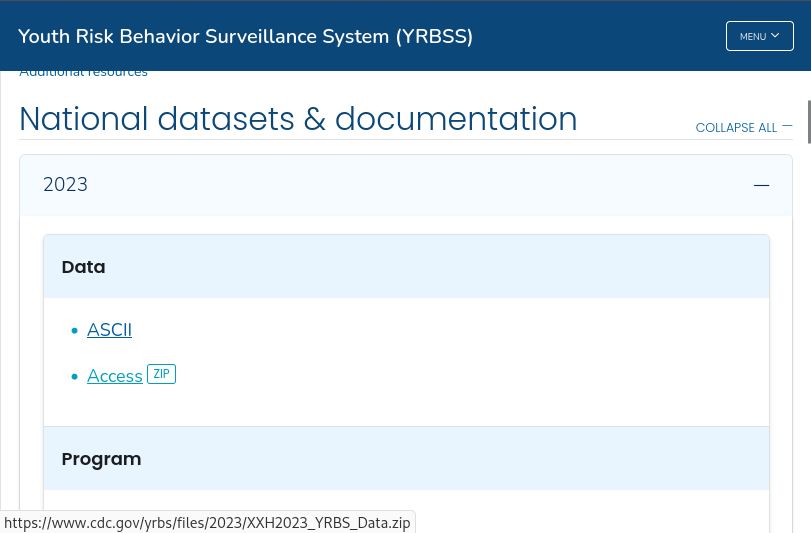
When we mouse over the “Access [ZIP]” link, we can see a small popup at the bottom left of the window displaying a URL, which indicates that this file is statically-linked:

Statically-linked files such these are the most likely to be picked up by web crawlers, such as those run by the Internet Archive. We can confirm whether or not these data have already been archived by consulting the Wayback Machine before proceeding (see the Wayback Machine URLs Tab or the querying the CDX API sections):
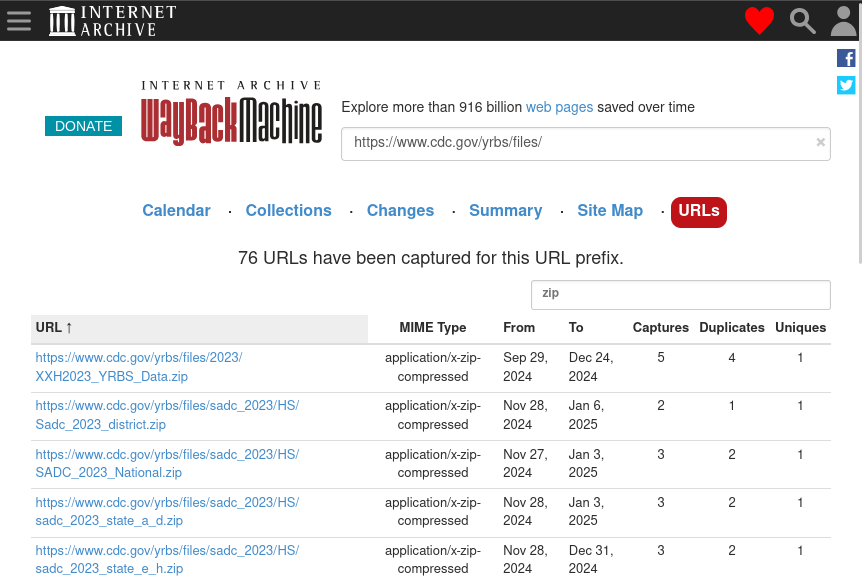
If time is extremely limited, then assume that pages and files that are statically-linked have already been captured and move on.
6.2 Medium concern: links from dynamic webpages
Many webpages do not serve static content but rather dynamically generate the page using JavaScript. Many social media pages operate like this to slowly feed users a stream of content rather than loading a lot of content all at once.
These pages can be identified through the following methods:
- Do pieces of the page move around or appear / disappear as you navigate?
- Does the page loading indicator appear and disappear as you navigate?
- Install a JavaScript blocker such as NoScript and navigate to the page. Is it now broken?
Because these pages require user intervention for certain parts to load, they may not be picked up by basic web crawlers. However, these pages can be captured using browser automation tools like Selenium or hide navigable tags and URLs in their source code (for example, using CSS), so there is a chance that they may be picked up by more sophisticated web crawlers.
6.3 High concern: data behind portals
Data that exist behind portals requiring user interaction via the mouse or keyboard are of high concern, since basic web crawlers may not be able to interface with the portal depending on how it is set up. Unlike dynamically-loading pages, it’s more likely that these portals behave in drastically different ways. Of special concern are portals that use JavaScript to operate, though these are hard to identify without looking into the source HTML code behind a page.
Portals can be identified by their distinctive buttons and menus that do not display URLs at the bottom left of your browser window when your mouse hovers over them. Most of the time, these are HTTP <input> tags. See the MDN page on HTML <input> types for more examples of how these look in your browser.
See below for some examples of portals with their distinguishing features highlighted:
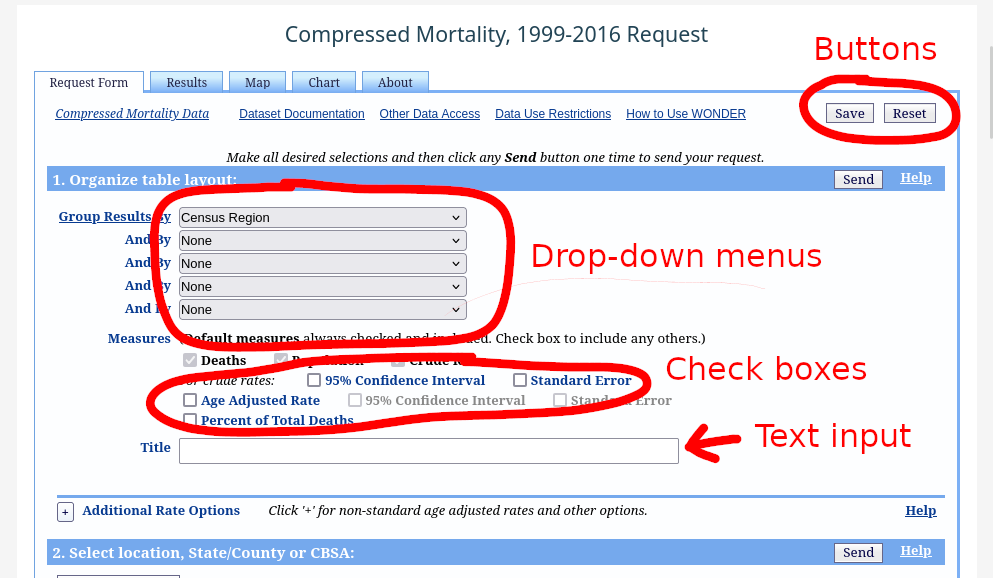
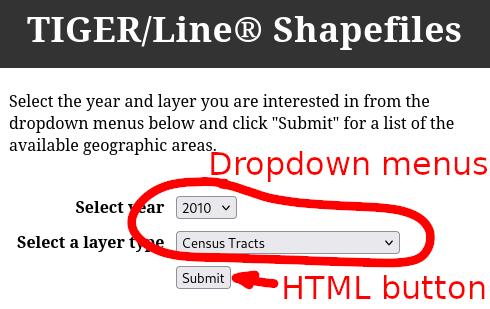
6.4 Highest concern: data served only by APIs
In some cases, data behind portal can be crawled if there is not heavy use of JavaScript or if the data is accessible through static links (for example the TIGER/Line data). However, data behind APIs most likely cannot be crawled, as there is no single standard for designing an API. Many different API protocols exist for data of different purposes, for example OpenAPI/Swagger, CKAN, GraphQL, etc.
As such, knowledge of
- What API protocol is being used (if the API is even using a standardized protocol to begin with),
- Which endpoints are responsible for serving the data of interest, and
- How to write a program to interface with those endpoints API and scrape data
are all required in order to scrape data from an API, and all of these generally require human intervention.
As with the previous sections, some data that are accessible from APIs can also be retrieved through other means. When determining what data is most vulnerable, be sure to check if this is true for any given API before assigning it a high priority.
6.5 Summary
- When deciding what pages and data to prioritize for preservation, think: is a robot able to retrieve this data on its own, without human intervention? If so, then it’s likely that one already has and that you will be able to retrieve that data later.
- To reiterate: if time is extremely limited, then assume that pages and files that are statically-linked have already been captured and move on.